2021-1122-BDA
BDA: Practical Dependence Analysis for Binary Executables by Unbiased Whole-Program Path Sampling and Per-Path Abstract Interpretation
作者:ZHUO ZHANG, WEI YOU, GUANHONG TAO, GUANNAN WEI, YONGHWI KWON, XIANGYU ZHANG
单位:Purdue University, Renmin University of China, University of Virginia
会议:OOPSLA 2019
链接:https://www.cs.purdue.edu/homes/zhan3299/res/OOPSLA19.pdf
传统的二进制别名分析技术如VSA,Alto由于过于保守,会带来大量的over-approximation。而单一路径上的代码/数据依赖关系是比较容易确定的,因此作者从程序中采样出大量路径并对每条路径进行抽象解释,分析出该路径中的依赖关系,最后通过合并采样的路径得到程序中的依赖关系。分析结果大大降低了over-approximation,而其漏报率由概率保障(采样分析的路径越多,漏报越少)。
Introduction
通过Program dependence analysis能够判断两条指令之间是否存在依赖关系。Binary program dependence analysis比source level dependence analysis更具有挑战性,因为binary中缺少符号信息,结构体、变量、参数都变成了寄存器和内存访问、间接控制流,使得Program dependence analysis在binary中更加困难。
Binary dependence analysis中的关键挑战是memory alias analysis,其可以判定内存访问指令是否会访问同一块memory location。在此之前,大多数使用Value Set Analysis(VSA),一种静态分析方法,来解决内存别名问题。其通过计算每一条指令的取值范围,别名的内存访问指令拥有相同的值集。虽然VSA是sound的,但是其在实际使用中有很大的局限性,会产生大量的误报。
soundness虽然在部分场景是必要的(如语义等价的code transformation),但在一些soundness不是至关重要的场景下(如函数识别、漏洞检测、fuzzing、协议逆向等),使用dependence analysis with probabilistic guarantees可以提供性能和可用性之间的trade-off。
因此在本文中,作者提出了a binary level program dependence analysis technique with probabilistic guarantees。其通过随机采样,生成不同的路径(由于是if-else时随机选择,因此可能难以探索较长的路径),并对每条路径进行抽象解释。最后由一个 context-sensitive and flow-sensitive 的 posterior dependence analysis 对每条路径中的抽象变量进行合并,得到最后的结果。可以通过增加path sampling的数量减少漏报,并通过strong updates来遏制误报。
Motivation
一个在binary dependence analysis中,甚至说是binary analysis中普遍存在的关键挑战是决定内存访问指令的points-to relations。
Limitations of Existing Techniques

内存别名分析的核心(也是downstream dependence analysis)在于静态决定内存访问指令中地址的possible runtime values (PRV),其可能是寄存器或memory location。然而这个问题在通常情况下是undecidable的。
Alto
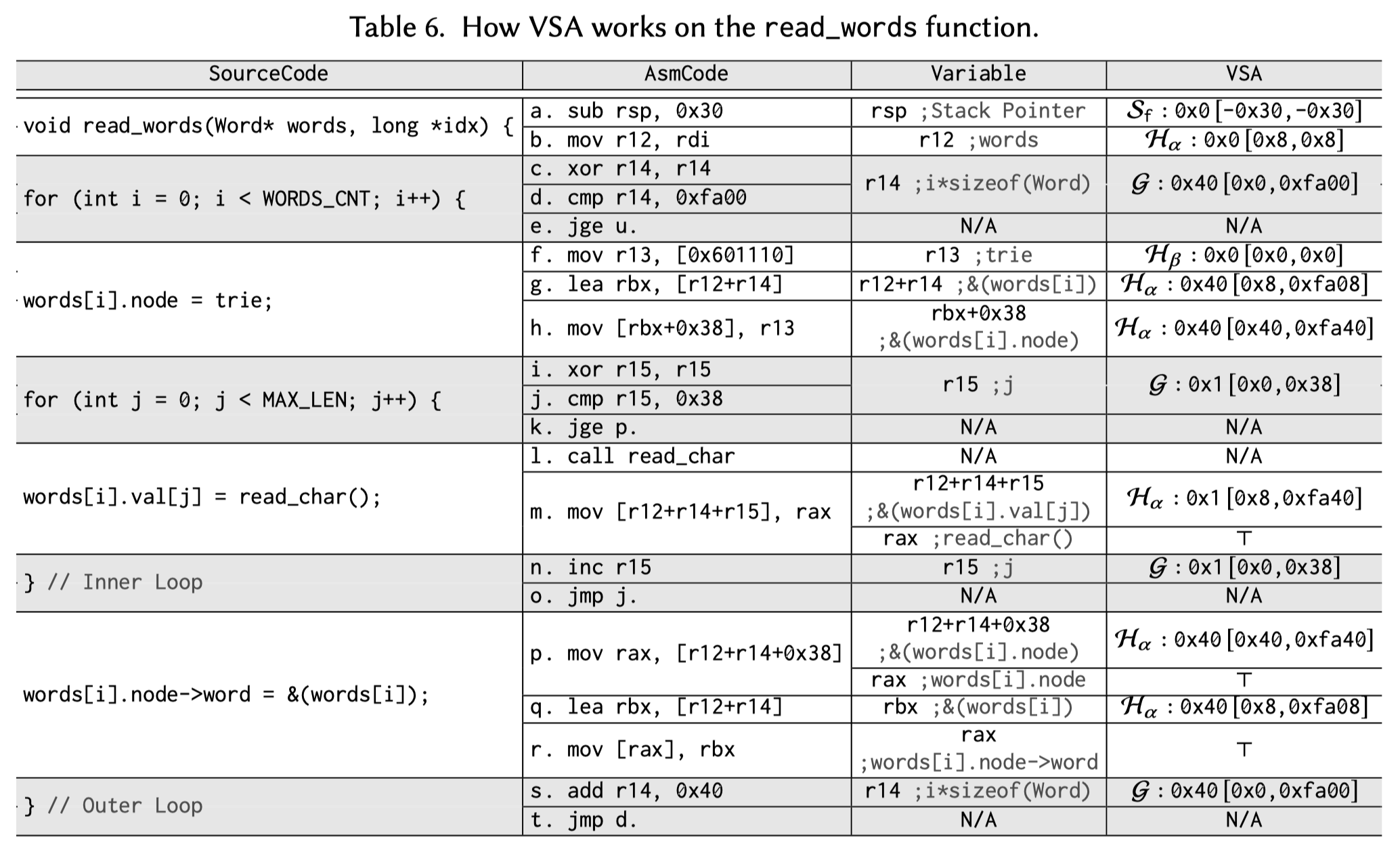
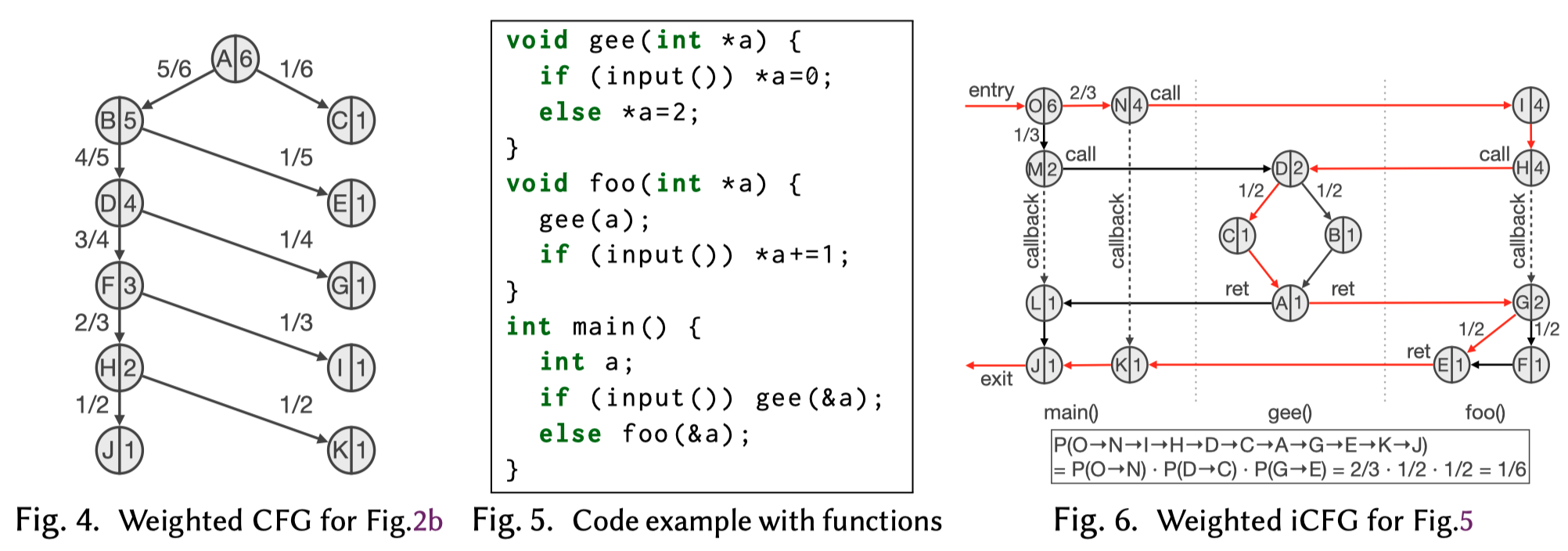
Alto对变量使用 address descriptor <inst, OFFSET>的形式进行抽象表示。inst代表获得base value的指令,OFFSET代表base value可能的偏移集合。如Figure 1的13行中将dict->words读取到rdi,通过两条指令完成,指令i加载base dict,指令j加上words字段的偏移(8)。因此rdi的address descriptor为<i,{0x8}>。
Alto只根据寄存器操作计算PRV,而不考虑内存读写。当指令i从内存地址中加载值到一个寄存器后,将该寄存器的PRV重置为<i,{0x0}>,而不会考虑最近对这个地址的写入。因此Alto会保守的认为一个new descriptor会从任意的地址中读取,并不会依赖任何的memory write,会造成大量的误报。
VSA
VSA通过抽象解释,对寄存器和内存的操作进行建模计算PRV,其通过strided interval s[lb,ub]来表示变量的PRV,lb和ub分表代表下界和上界,s为间隔。因此,其可以用一组整数表示 {lb,lb + s,lb + 2s, …,ub}。strided interval与内存区域关联,可能是heap、stack或global。同时引入⊤,代表all possible value。
两个strided intervals的加法规则为gcd:
$SI 1 = s 1 [lb 1 ,ub 1 ]\ \ \ SI 2 = s 2 [lb 2 ,ub 2 ]$
$SI 3 = gcd (s 1 ,s 2 ) [lb 1 + lb 2 ,ub 1 + ub 2 ]$
The major limitation of VSA is over-approximation.
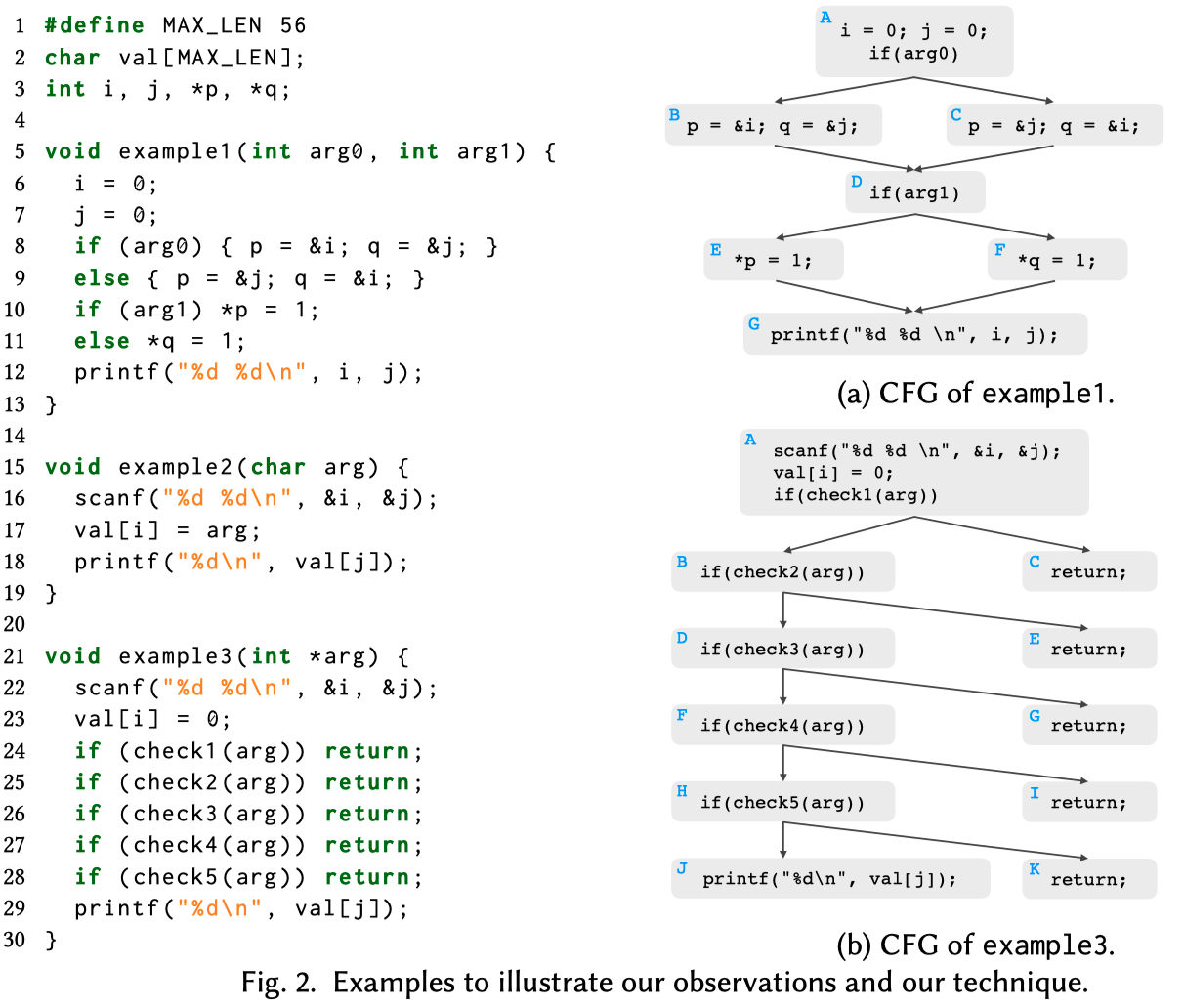
Observations
不同的分析需要不同的sensitivity,最简单的type inference可以是path-insensitive,context-insensitive,甚至flow-insensitive;比较复杂的dependence analysis则是path-sensitive,context-sensitive,flow-sensitive的。
一个重要的观察是a dependence relation, which means dependence through memory in our context, can be disclosed by many whole-program paths. 换而言之,即使是context-sensitive,path-sensitive,分析的敏感度仍然受限。依赖关系可能由多条paths决定,且可能是input sensitive。
Our Technique
作者提出了一种sampling based的抽象解释方法用于dependence analysis。BDA对程序中的路径进行跨过程的采样,不同路径的可能性通过正态分布而不考虑路径的长度。对于每一条采样的路径,抽象解释每条指令可能的值。
抽象解释时,
- 输入从预设的分布中随机采样
- stack memory用stack frame及offset表示
- heap memory用allocation site表示
- 抽象value根据指令的语义进行更新
- memory reads/writes通过抽象store建模
BDA的抽象解释并不依赖与strided intervals,而更接近于混合执行,对每条指令计算一个抽象value。
BDA最后还会进行posterior分析,以消减采样时带来的误报。
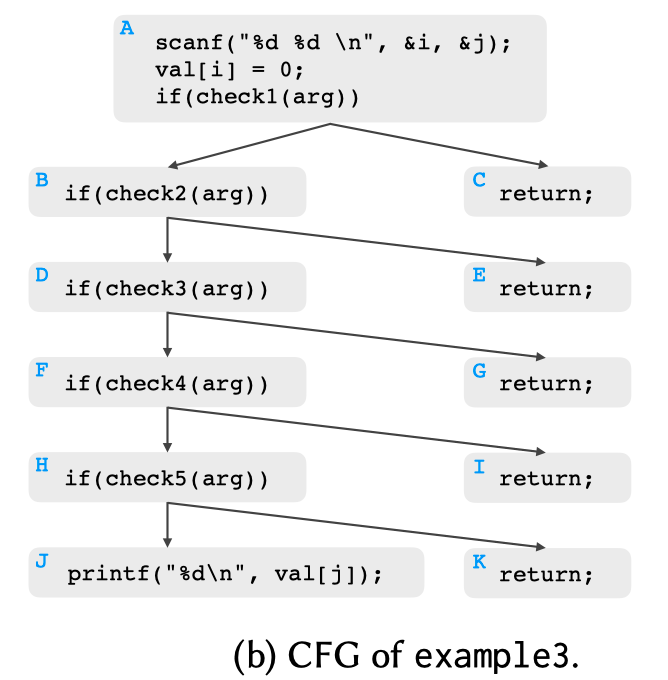
naive sampling algorithm对每一个分支都使用1/2概率的方式决定,是行不通的,A→B→D→F→H→J只有1/32的概率。
Design
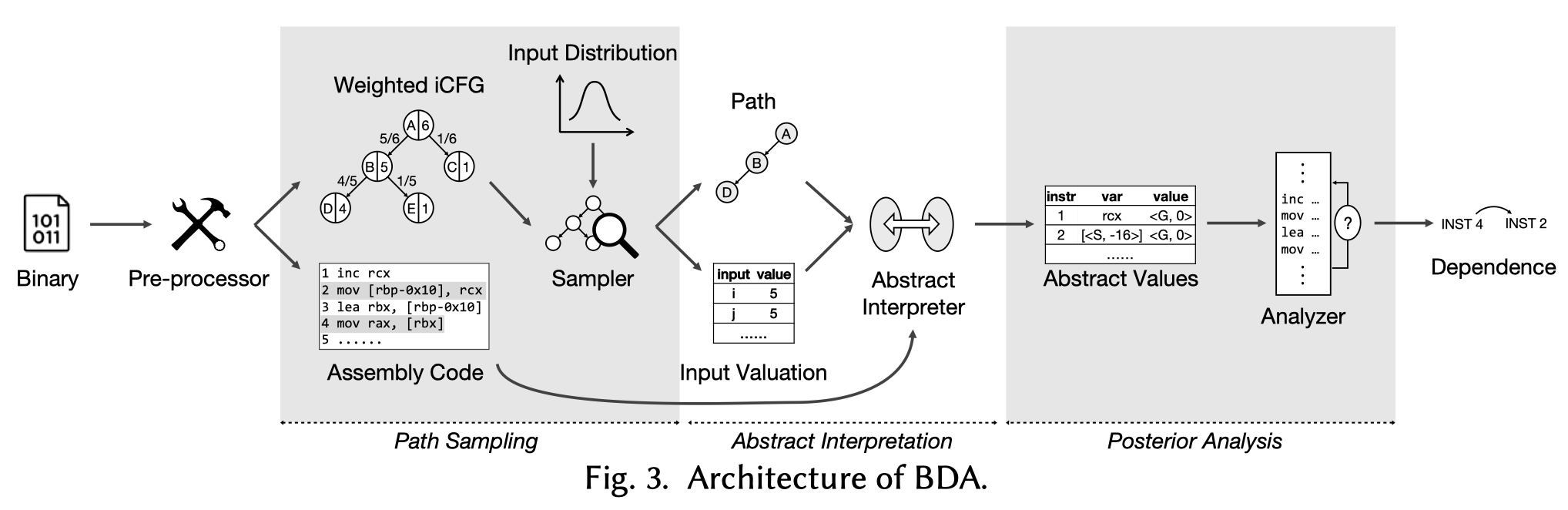
pre-processor生成iCFG,iCFG中每个基本块的权重为从该块出发的路径数量。采样器根据block的权重进行采样。
Path Sampling
Addressing Practical Challenges
- Handling Loops
- Handling Multi-Exits
- Handling Indirect Calls
- Edge Coverage
- Sampling External Inputs
- Probabilistic Guarantees in Practice
Abstract Interpretation
自己搞了个low-level language,并将程序lift到这个IL上。并沿着sample到的路径逐指令抽象解释,具体的规则如下:


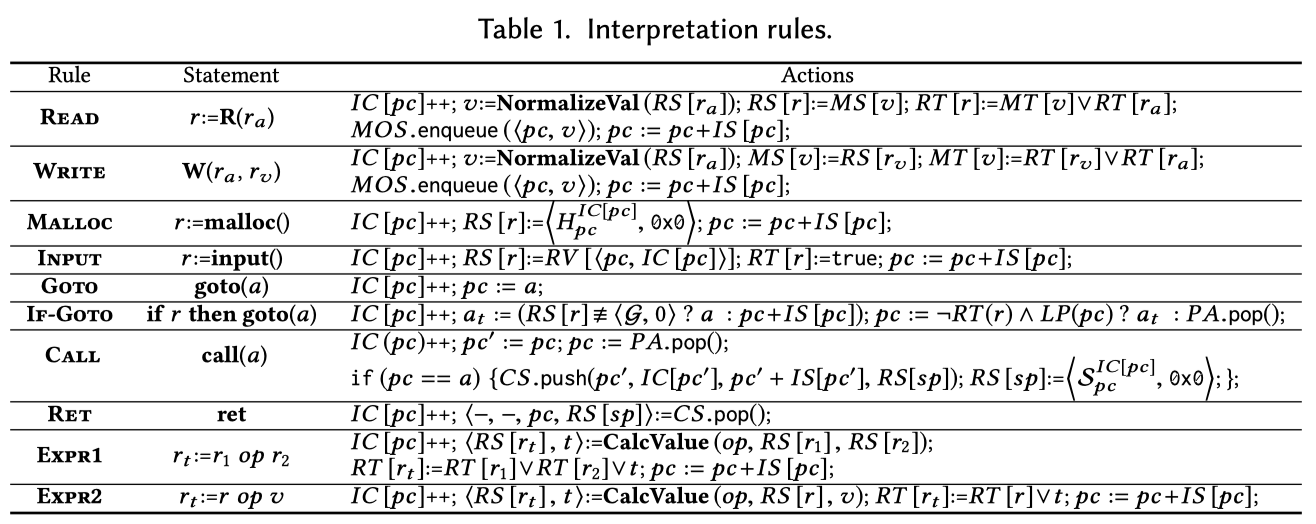
Read和Write的处理使用了NormalizeVal,将ra中的地址归一化,使得对同一地址的访问能够关联起来。
Rule Read describes the semantics of memory read. It invokes an auxiliary procedure NormalizeVal() to normalize the abstract (address) value in register r a , denoted as RS[r a ]. As shown in Figure 9, if the value is a global or heap value, it is returned directly. Otherwise, it is checked to identify the enclosing stack frame of the address. Note that it is common for an instruction to access a stack location beyond the current stack frame (e.g., access an argument passed from the caller function). The procedure traverses the stack frames from the top to the bottom till it finds a frame on which the offset becomes negative. After normalization, the abstract value stored in the normalized address is copied to the target register r. The taint bit of r is the union of the taint bits of the normalized address and the address register r a . At the end, the pc is updated to the next instruction.
Example:
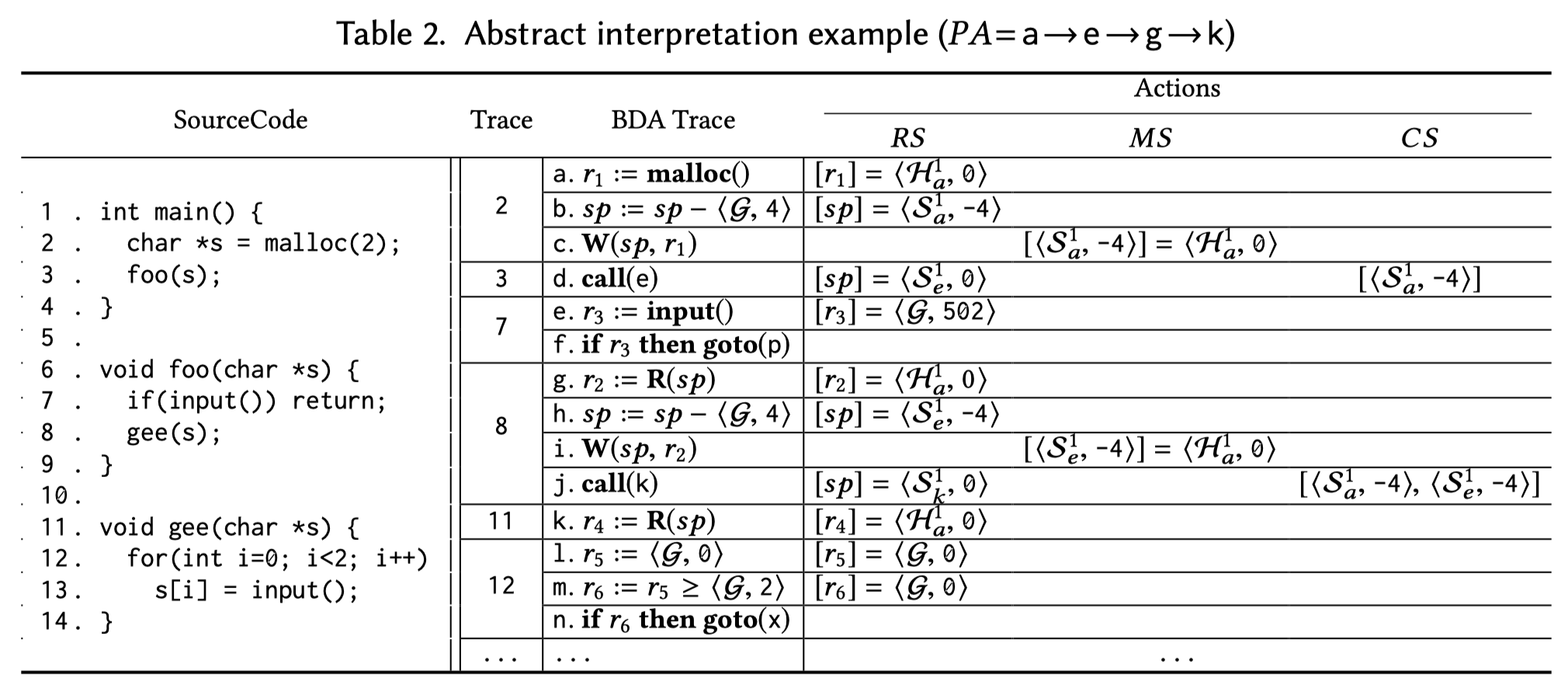
Posterior Analysis
对所有采样的路径抽象解释完成后,posterior analysis将完成dependence analysis,其通过一种flow-sensitive, context-sensitive, and path-insensitive的方式将不同路径的抽象变量收集起来。
Example:
如Fig. 10,BDA通过抽象解释两条路径2 → 3 → 4 → 5 → 6 → 8 and 2 → 3 → 7,发现了7→4,5→4,8→2的依赖关系,由于路径不完全,遗失了8→4。Posterior analysis通过在line 3处,将这两条路径中的抽象变量合并,从而发现missing的依赖关系。

Evaluation
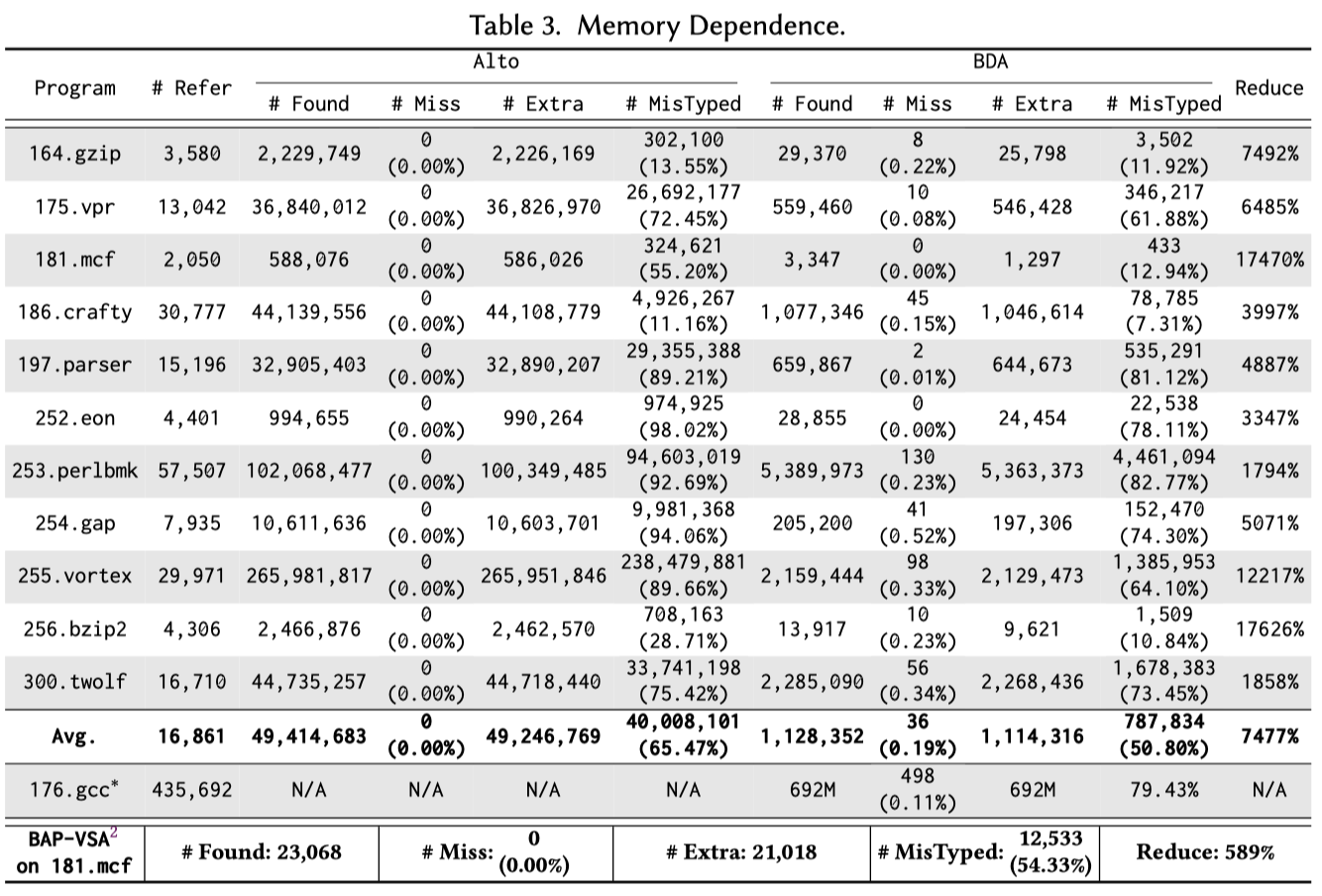
BDA用Rust实现,利用Radare2作为其反汇编的基础设施。与Alto和VSA进行对比,benchmark为SPECINT2000。并与IDA对比间接控制流转移的目标分析,与Cuckoo对比识别malware的hhidden malicious behaviors。
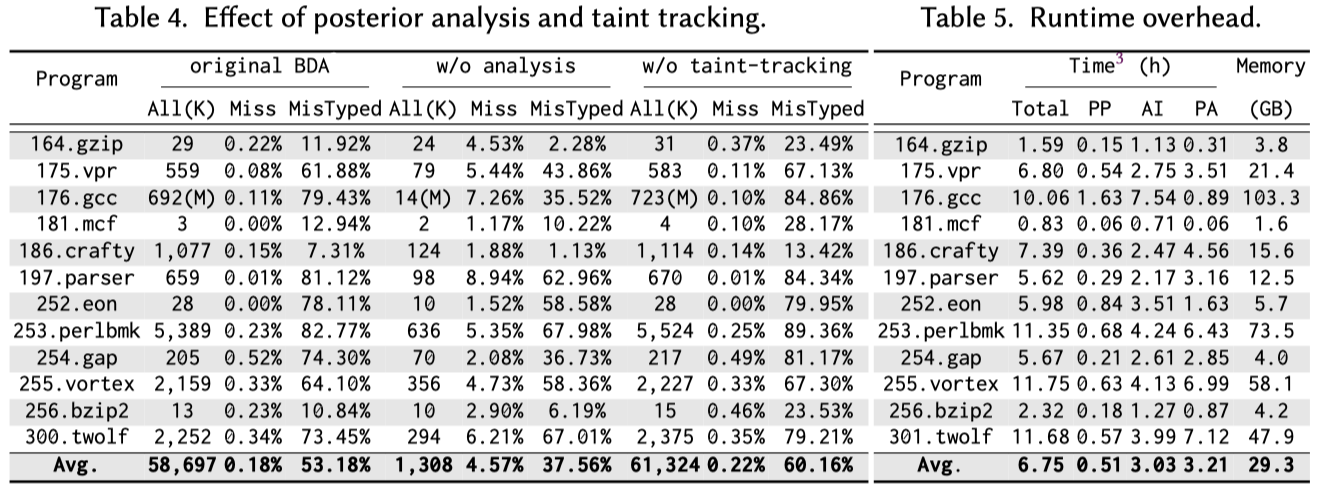
Conclusion
本文提出了一种对二进制程序切实可行的program dependence analysis方法,其使用一种新型的全程序路径采样算法并对每一条路径进行抽象解释以发现程序中的依赖关系。通过实验表明BDA比state-ofthe-art技术VSA有可观的提升。其能够应用于indirect call target identification and malware behavior analysis.
BDA未开源